
| Search website: | |
|
|
Advanced Server Software
|
Also see the dedicated surgemail.com website with knowledge base and ticketing system

Major topics.
- How it works
- How to turn it on
- How to tune it for your users (help I've got more spam, or more bounces)
Technical Info:
- New commands and settings
- Brief outline of how a message is processed
- Features to stop cracking local accounts and sending out spam
- Explanation of the X-SpamDetect header
- How to disable the new system!
- How to convert your local.rul file to sf_mfilter_local.txt
MyRBL / Smart Filter -- New Spam Handling Process
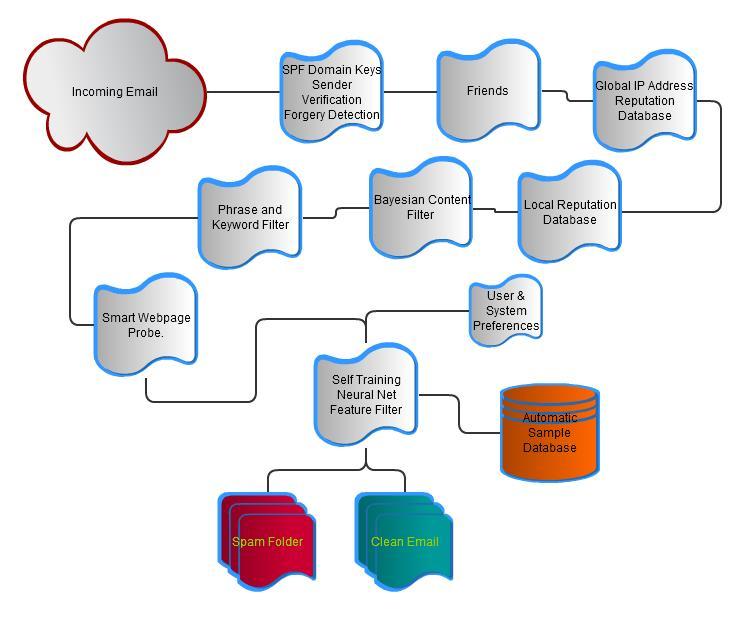
How it works - Summary
Each incoming message is analyzed for as many 'features' as can be found that have significance, then the pre generated feature processor rule file combinese those features to figure out the probability that the message is SPAM or not. If the message passes a minimum level then it is placed in the users 'spam' folder and the sender is notified by a url (with CAPTCHA) this allows a real sender to bypass the 'spam' folder and ensure delivery.
The user can also access their spam folder via IMAP or the SurgeWeb email interface if they suspect a message may have been miss classified
This system has several key benefits:
- No messages are blocked or dropped, failed deliveries due to filtering mistakes are enormously annoying, and no filter is ever accurate enough to allow this type of heavy handed mechanism.
- The user does not 'see' the filtered messages unless they wish to.
- A real sender can easily get their message delivered directly to the users inbox by proving they are a human.
- By identifying many different 'features' using different modules/methods the results are more robust than any single mechanism for identifying spam.
- System admins can add their own 'features' and the system will correctly analyze the 'value' of those features so the systems reliability will not be degraded by 'one' badly chosen rule/score...
Filter Module Summaries:
- SPF Domain Keys Sender Verification - These systems allow the sender domain/ip address to be verified as genuine, although this doesn't stop all spam it can certainly stop a large bulk of spam and phishing by identifying the obvious forgeries.
- Friends - For each user we maintain a list of friends, messages from known friends are whitelisted automatically and delivered directly to the inbox, the list of friends is automatically updated by the server as it notices who you send email to, and what messages you move in/out of your spam folder.
- Automatically collected sample database - A sample database is automatically collected so that the filter rules can be tuned to match the types of spam and nonspam that are common on your server.
- Bayesian like content filter - Each day the database is used to re-tune the Bayesian like filter which works by statistically anlyzing the words and order of words. This filter does well with text content spam (phishing, scams etc)
- Phrase and Key Word Filter - This filter is manually created and regularly updated to target phrases common to spam, this filter is also good at catching common scams and any common text based spam messages.
- Web page probing - This filter carefully examines messages to find url links which are 'unknown' to it, it then probes the web pages in question to see if they contain commonly spammed products (drugs etc)
- SPF and Domain Keys sender verification - Sender verification methods are used to identify people forging email, this allows non genuine email to be quickly identified and blocked. Most spammers forge email identities in some way.
- Feature rule file - This rule file identifies many different features of email (like capital letters in the subject), these features are then fed into the self tuning feature processing module...
- Self tuning feature processing - This module takes all the information from the modules above and combines the results based on analysis of the sample database to figure out the probability of a message being spam based on all the features it exhibits. Each day the rules are recreated based on your local spam samples, and combinational rules are created automatically.
Some more technical details
How sf_mfilter --> feature_gen.dat (note aspam_mfilter.txt is replaced with sf_mfilter.txt in this version)
The rule file sf_mfilter.txt now produces a list of significant features for any email message, the features are then analyzed using the rules in feature_gen.dat to come up with a 'score'. So the scores are not 'hard coded' into sf_mfilter.txt
The file feature_gen.dat is created by analyzing sample messages from your own server, so lets say we have a feature "blob" which on your server correlates 98% with spam, and on my server correlates 20% with spam (so in other words an email on your server with the feature 'blob' is a spam email 98 times out of a hundred, and on my server 80 times out of a hundred its not spam. Then on your server the score in x-spamdetect header will be something like "plus 10" for an email with 'blob' and on my server it will be 'minus 4'...
The feature 'blob' might relate to something like the length of the 'to' header, or weather or not the spf tests passed etc...
Then, in addition to simple rules the automatic process generates combinational rules based on your sample messages, so it might notice that a message which is from yahoo and has a long "To" header, is always spam. These 'combined' rules are also used to further increase accuracy.
Built-in RBL / Reputation system
SurgeMail now includes it's own RBL system (Realtime Blocking List) and Reputation system. This is a two level database, a local database based on each server, and a reporting system and DNS based query system to merge data between all SurgeMail servers in the world.
This system classifies all ip addresses into one of 5 colors
Unknown = 98% spam
Blue = less than 10 days old, nothing significant known (typically 70% spam)
Brown = 95% spam
Orange = 40% spam
Yellow = 20% spam
Black = 99% spam
White = Less than 4% spam
As most 'real' email comes from servers you talk to all the time this system quickly identifies the trusted mail servers that never send spam so that messages from those server will be very unlikely to be accidentally classified as spam.
The advantages this has over traditional RBL services (which should also be used of course)
It is free to use
It makes use of the many users clicking 'spam/not spam' on messages as they read them to help identify spam more accurately.
It provides both positive and negative indications for the spam filter, this is much more valuable than purely negative responses as given by many rbl services because the bulk of spam comes from 'unknown' transient ip addresses, so the significant information is the list of known mail servers that regularly send 'non' spam.
It is also a long term reputation rbl, so instead of automatically forgetting everything every 2 days like many rbl systems we try and store a long term record of stats for each ip address. This database can be searched here: http://reputation-email.com/reputation/index.htm
Management commands/settings etc
tellmail commands:
tellmail sf_train - Rebuild feature_gen.dat from sf_mfilter.txt using local data in 'train' subdirectories
tellmail sf_compare - Test feature_gen.dat on train sub directories.
tellmail friends_url - Show a sample URL for unblocking a message, use to test your web access/ports are set correctly.
New Optional settings:
g_myrbl_share "true" - Share IP reputation information with netwinsite.com (strongly recommended, this setting really helps contribute to the wide area rbl which all customers benefit from)
g_sf_generate "true" - Generate feature_gen.dat locally rather than using a standard generic one from NetWin. This is worth setting once you have a reasonable sample collected (surgemail automatically collects sample messages within a few days)g_friends_lang_auto "true" - Guess the users language(s) by observing messages from each users friends, then add a tag if the user receives a message which is primarily in a language that the user does not have listed. The users language settings are prefixed with the word 'Auto,' when this setting is used so users who have manually set their language(s) will not get adjusted.
Brief outline of how a message is processed
- Get color from RBL/Myrbl/Surbl etc...
- Run sf_mfilter.txt to find 'features' of message
- Score message using feature_gen.dat and then bounce with url or give to user.
- Run mfilter.rul file
- If from friend accept
- If exceeds friends setting then bounce message and store in 'spam' folder.
- Deliver to inbox
Features to stop cracking local accounts and sending out spam
- g_breakin_enable "true" - used to stop a spammer sending from multiple (3+) ip addresses. (g_breakin_white can be used in rare problem cases, e.g. g_breakin_white "user1@domain.com,user2@domain2.com,*@domain3.com")
- g_user_send_warning - alert manager when user sends too many messages.
- g_user_send_max max="500" - limit users to a modest daily total
- g_safe_smtp "true" - stops a user logging into surgemail to send email without first logging into imap or pop, this will stop 'most' spammers in their tracks even after they hack into an account (but not all) It won't usually cause people problems but it might on rare occasions.
Explanation of the X-SpamDetect header
Here is an example header:
*******: 7.8 sd=7.8 [194]99%13.1(!9,46) [126]10%-7.2(!33,108) [38]87%5.4(X-myrbl:unknown)"
This shows a score of 7.8, then a list of the rules that were applied seperated by spaces. There are two sorts of rules, simple rules and combination rules.
A combination rule looks like this: [rulenumber]percent%score([!]a,[!]b)
rulenumber = this rule number as listed in feature_gen.dat
percent = The percent of messages that have spam if this rule is true
score = The score which is generated using the percent. Anything over 50% generates a positive score, below 50% generatese a negative score.
(a,b) = The two rule which were true that made this combined rule true, ! signs are used to indicate 'not'.
A simple rule looks like this: [38]87%5.4(X-myrbl:unknown)
rulenumber = this rule number as listed in feature_gen.dat
percent = The percent of messages that have spam if this rule is true
score = The score which is generated using the percent. Anything over 50% generates a positive score, below 50% generatese a negative score.
(a:b) = The header and value that were 'matched' that made this rule true, if no header is specified then it's a feature as defined in spf_mfilter.txt
The total sd=7.8 is not a simple sum of rules, but rather an 'average' of the rules that matched. Offset by '4' to the right, e.g. sum(scores)/n+4
How to enable the new system (for those upgrading)
- Install Surgemail 5.0 or later
- Optionally set g_sf_generate "true" if you wish to generate your rule files from your own samples (which are automatically collected)
- If you are using friends we recommend you set friends to level 6
- Use tellmail friends_url to test if your external web address is accessable so a sender who is incorrectly blocked can bypass the problem.
- Convert your local.rul file (if you have one) to sf_mfilter_local.txt, see section below on sf_mfilter_local.txt (or try without any local extensions as you may find you don't need them)
- Global or user based friend.msg response templates are not used (as they would probably give the wrong instructions to confirm by email instead of using the url). So in the unlikely event that you need to tailor the friends response you (or any users) will need to re-tailor the message in the web interface as usual.
How to disable the new system (if you must)
To disable the new Smart Filter mechanisms and return to the old behaviour!
Only use these settings if you really must :-)
g_myrbl_disable "true"
g_sf_disable "true"
g_friends_byemail "true"
g_spf_byemail "true"
How to TUNE it for your users/system (help I've got more spam or more bounces)
- Install Surgemail 5.0g3 or later and use the config checker!
- Move 'webmail' users to 'SurgeWeb' (this gives easy access to the spam folder, and training buttons), encourage all users to try using surgeweb to read their email. To get to SurgeWeb they use a url like this: http://your.mail.server/surgeweb
- Make sure all users understand how to get to their 'Spam' folder
(which will contain blocked messages!)
- SurgeWeb users can see it automatically
- IMap users will see a folder called 'Spam', dropping message in/out of that folder will train the message as spam/not spam.
- POP users are stuck, see details below.
- For POP users there are three choices.
- Don't filter their email just 'tag' it in the subject as normal. (This is safest)
- Set a default friends rule at about 9 or higher and set G_USER_STATUS_SEND "1" (units=days) which will send them a list of message in their 'spam' folder once a day. This is also a good option!
- Lastly encourage pop users to change to SurgeWeb or IMAP so they can use folders! (This is really the option when option '2' doesn't satisfy their needs)
- HELP it's bouncing too much stuff -- This probably means you or users have 'bounce' rules, upgrade to 5.0g and turn on the recommended features including g_spam_nobounce "true"
- HELP I'm getting more spam now -- This probably means you used to bounce email based on score (which was bad, naughty you! :-), now you have to turn on a global/domain/user rule for friends to have the same effect. If you are a 'pop' user (or most of your customers are) then set the level higher, e.g. '9' because as a pop user 'you or they' cannot see their spam folder to find false positives except by checking the daily status email!
- Help local messages are marked as spam -- This means you are missing these two settings: g_smite_skip_relay "true" and g_smite_skip_auth "true"
How to convert your local.rul file to sf_mfilter_local.txt
You can tailor your own rules still with this new system however, we suggest you consider the following, try using the builtin rules first and see how they perform.
If you are going to use 'local' rules then you must first enable local training:
g_sf_generate "true"
When adding rules (e.g. converting an existing local.rul file) you will need to change the actions to choose from the various possibilities
- Add a manual score - call feature_manual(0.8, "Manual addition")
- Add a self tuning score based on your spam sample - call feature_add(1.4,"featurename")
In the second case the score '1.4' is ignored. So the recommended method is to convert all call spamdetect(x,y) statements to call feature_add(x,y)
In the first case the value 0.8 is NOT the value added to the spam score, it is the probability that such a message is a spam message, so a value of 0.99 might add 12 to the spam score. A value above 0.5 will add a positive value to the spam score, a value below 0.5 will decrease the spam score. Examples:
call feature_manual(0.95, "Probably spam")
call feature_manual(0.7, "may be spam")
call feature_manual(0.0, "almost never spam")
call feature_manual(0.1, "Probably not spam")
You should only use 'manual' rules when the feature is so 'rare' that your sample data does not give useful figures on it, and in that case, the rule is probably of little or no value, so we suggest you don't use it at all :-) But there are exceptions where the sample spam messages will tend to give the wrong result (as the sample is not entirely random) so a manual rule might make sense.
A good example of when to use manual rules is when using an RBL service etc so you know that the probability of it being spam is very high you can improve results by using the manual rule with a nice high value like 0.9
Then run the following commands:
tellmail sf_train
tellmail sf_compare
The first will generate a feature_gen.dat rule file and the second will use it to compare results with the sample spam folders.
If you examine 'feature_gen.dat' after the sf_train command you will be able to see what surgemail thought the feature was and how significant it was (sig = the number of messages with the feature), A feature with a probability near 0.5, or one that occurs less than 20 times in the sample is probably of little point... Near 0.0 means the feature implies the message is not spam, near 1.0 implies the feature correlates with spam...
We are always interested in new features you make up that prove useful. Be cautious that some features can give misleading results due to the nature of the sample messages.
- copy local.rul to sf_mfilter_local.txt
- Search/replace "spamdetect(" with "feature_add("
- copy local.rul to sf_mfilter_local.txt
- Search/replace "spamdetect(" with "feature_manual("
- Change each spam score -x to +x into a probability instead (0.0 -> 1.0) of spam.
Convert into automatic rules instructions (recommended)
Convert into manual rules instructions:
Tips for users to avoid spam:
Never put your email address on a web page, instead use a service like this one: http://www.emailmeform.com/
What if it doesn't work at all ?
If the scoring is completely blank or if you see this text in the headers:
X-SpamDetect: : 0.0 sd=0 feature_gen.net (or .dat) is blank or missing, update from netwinsite failed see netwinsite.com/surgemail/help/myrbl.htm for help
It might mean you are running a new build with the new spam handling mechanism, and most likely it's failed to pickup it's main rule file so it's not applying any rules at all.
It might fail if you don't have updates, or if you have a firewall blocking port 80 outgoing connections from your server. Once you fix the problem you can 'trigger' an update automatically by deleting aspam_update.done and restarting surgemail.
The two files you need are:
sf_mfilter.txt
feature_gen.net
They should automatically be fetched from netwinsite but that 'can' fail if
your firewall is blocking port 80 connections. In which case you could download
them manually then restart surgemail.
https://netwinsite.com/surgemail/sf_mfilter.txt
https://netwinsite.com/surgemail/feature_gen.net
Or You can disable the new system with this setting: g_sf_disable "true"